
برای مقادیر فرد، پس از مرتب کردن آنها، میانه عدد وسط می باشد. برای تعداد زوج، میانه برابر با میانگین 2 مقدار میانی پس از مرتب سازی همه مقادیر است. مثالهای زیر از این مسئله را کاملاً روشن می کند.
میانه: مثالهای ساده داده

● V1 دارای مقادیر 1 تا 5 است که بصورت صعودی مرتب شده اند. میانه – مقدار متوسط – 3 می باشد.
● V2 دارای مقادیر 1 تا 6 است که بصورت صعودی مرتب شده اند. میانه 3.5 است که میانگین 2 مقدار میانی 3 و 4 می باشد.
●V3 همان V2 با جایگزینی 100 به جای 6 است.این عمل بسیار در میانگین تاثیر دارد اما دو مقدار وسط -که از این رو میانه- ثابت باقی می ماند.
● V4 مقادیر V3 را به ترتیب تصادفی نگه می دارد. میانه، میانگین 2 مقدار میانی نیست،مگراینکه ابتدا آنها را مرتب کنیم.
● V5 شامل مقادیر دوتایی است: مقدار1، پنج بار اتفاق می افتد. از آنجا که مقادیر مرتب شده اند، میانه برابر با میانگین 2 مقدار میانی (1 و 1) می باشد.
توجه داشته باشید که برای V2 تا V4، میانه مقداری است که 50٪ بیشترین مقادیر از 50٪ کمترین مقادیر، را از هم جدا می کند. به نظر می رسد این برای بیشتر متغیرهای (نیمه) پیوسته که در داده های دنیای واقعی پیدا میکنیم، صدق میکند مانند
● درآمد دقیق ماهانه به تومان،
● وزن بدن برحسب گرم یا…
● سن برحسب روز.
با این حال، ممکن است برای داده های بسیار گره خورده(مانند V5) یا تعداد کمی از مشاهدات کاملاً قابل قبول نباشد.
رابطه میانه و میانگین:
ما به صورت خلاصه درباره مزایا و معایب میانه ها در مقابل میانگین ها، بحث خواهیم کرد. بیایید ابتدا ببینیم که آنها در وهله اول چگونه با هم ارتباط دارند. این بیشتر به چولگی توزیع فراوانی، برخی متغیرها بستگی دارد:
*میانه برابر است با میانگین
برای متغیرهای متقارن توزیع شده که حاکی از چولگی برابر با 0 است. هیستوگرام نشان داده شده در زیر این نکته را نشان می دهد.

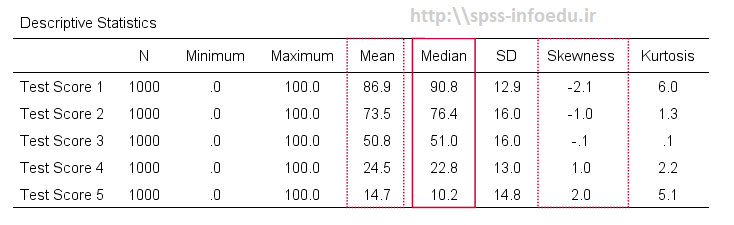
اصولا چولگی برای این 1000 نمره آزمون صفر می باشد. برای مثال میانگین نمونه (M) = 50.8 می باشد در حالی که میانه (Me) = 51.0. خطوط قرمز نشانگر آنها در محور x
قابل تشخیص نیستند.
هنگامی که مقدار چولگی قابل توجه باشد الگوهای مختلفی رخ می دهد. اولاً ،مقدارمیانه از میانگین کمتر است. برای متغیرهای باچولگی مثبت به مانند زیر نشان داده شده است.


بنابراین نمرات بسیار پایین میانگین را “پایین می کشد” .اما میانه تحت تاثیر اینها نمی باشد.
میانه: نقاط قوت و ضعف
تا اینجا، این مقدمه به طور ضمنی به برخی نقاط قوت میانه در مقایسه با میانگین اشاره کرده است:
- میانه، نسبت به نقاط دور حساس نیست. بنابراین شاید متوسط حقوق برخی افراد به دلیل وجود یک میلیاردرزیاد باشد. من ترجیح می دهم میانه حقوق را در این مورد بدانم.
- میانه، تخمین واقع بینانه تری از آنچه این افراد تمایل دارند به دست آورند می باشد.
- میانگین فقط برای متغیرهای کمی قابل استفاده است. میانه ها برای متغیرهای ترتیبی نیز،مناسب هستند. با این حال، متغیرهای ترتیبی معمولاً دارای تعداد زیادی پیوند هستند (مقادیری که بیش از یک بار اتفاق می افتد).
برای چنین متغیرهایی، ممکن است میانه ها گمراه کننده باشند، که در زیر نشان داده شده است.

اگرچه رتبه معلم B بسیار بهتر از رتبه معلم A اما میانه نمرات آنها یکسان می باشد.
جدا از این نقاط قوت ، میانه ها دارای نقاط ضعفی نیز هستند:
- میانه ها برای محاسبات عددی نامناسب هستند. به عنوان مثال ، مبالغ را می توان از طریق میانگین ها و نمونه های اندازه گیری محاسبه کرد اما از طریق میانه ها نمی توان محاسبه کرد. تفاوت بین 2 میانگین به راحتی قابل تفسیراست اما تفاوت بین 2 میانه به سختی قابل درک می باشد.
- چنانچه گره وجود داشته باشد ، متغیرهای بسیار متفاوت ممکن است دارای میانه های مشابه باشند.
- در واقعیت ممکن است میانگین وجود نداشته باشد. به عنوان مثال ، اگر دو نفر 0 و 1 فرزند داشته باشند ، میانگین آنها 0.5 فرزند است.
- گفته می شود میانه از نمونه ای به نمونه دیگر نسبت به میانگین نوسان بیشتری دارد.
یعنی پایداری کمتری دارد و خطای استاندارد بزرگتری دارد.
یافتن میانه ها در Googlesheets
یافتن میانه ها بااستفاده از Googlesheets بسیار آسان می باشد. به عنوان مثال ، تایپ کردن MEDIAN (B2: B7) در هر سلول، منجر به بدست آمدن میانه سلولهای B2 تا B7 می شود. (با فرض اینکه تمام سلولهای غیرخالی حاوی اعداد باشند). چند مثال دیگر در این صفحه Google (صرفا جهت خواندن) نشان داده شده است.
یافتن میانه ها در spss
در SPSS ، بهترین دستور برای یافتن میانه Analyze—Compare—Means می باشد.
از این دستور برای ایجاد جدولی که طیف گسترده ای از آمار توصیفی شامل میانگین ، انحراف معیار ، چولگی ،کشیدگی و سایر موارد را نشان می دهد، استفاده کنید. به صورت اختیاری، این موارد برای گروههای جداگانه ای که با نام “لیست مستقل” تعریف شده اند گزارش می شوند.

به همبستگی مثبت زیاد بین چولگی و (میانگین – میانه) توجه کنید: میانه بزرگتر از میانگین است تا آنجا که یک متغیرباچولگی منفی تر(چپ) می باشد. الگوی مخالف “یعنی میانگین بزرگتر از میانه” برای متغیرهای باچولگی مثبت (راست) رخ می دهد. این مورد قبلاً با برخی از هیستوگرام ها بر اساس همان پرونده داده ای که در این جدول ارائه شده است ، نشان داده شده است.
بررسی آماری میانه ها: آزمون های علامت
از جمله مشهورترین روشهای آماری، آزمونهای t می باشد. اگر اختلاف بین 2 میانگین از نظر آماری معنی دار باشد، این آزمونها را انجام می دهید. اما اگر بخواهیم به جای استفاده از میانگین ها، میانه ها را آزمایش کنیم چه می کنیم؟ در این حالت ما با یکی از 3 آزمون میانه روبرو می شویم که گاهی اوقات آنها را آزمون علامت(نشانه) می نامند:
- یک ازمون علامت برای یک میانه مانند یک نمونه t برای یک میانگین است: این مورد میانه را با یک مقدار فرضی مقایسه می کند.
- آزمون علامت برای میانه های مستقل مانند آزمون t مستقل یا تحلیل واریانس یک طرفه برای میانه ها می باشد: که آزمایش می کند هنگامی که دو یا بیشتر از دو، جامعه دارای میانه برابر هستند.
- ازمون علامت برای میانه های مربوط به آزمون t با نمونه های زوج برای میانه ها مشابه می باشد: که آزمایش می کند هنگامی که 2 متغیر در افراد مشابه اندازه گیری شده است یا سایر مشاهدات دارای میانه های برابر می باشند.
آزمون علامت برای یک میانه اساساً مانند این عمل می کند:
- هر مقدار کوچکتر از حد میانه مفروض با علامت منفی (-) جایگزین می شود.
- مقادیر بزرگتر از حد میانه مفروض با علامت مثبت(+) جایگزین می شوند.
- اگر میانه فرضیه درست باشد، در این صورت حدود 50٪ از کل علائم باید منفی باشد.
- یک ازمون دو جمله ای بررسی میکند که آیا نسبت نمونه های مثبت از 0.5 متفاوت است یا خیر.

سایر آزمون های نشانه نیز از همین استدلال اساسی پیروی می کنند. آزمون های های نشانه چندان محبوب نیستند چرا که پیوندها برای آنها مشکل آفرین است و از نظر آماری دارای اعتبار کمی می باشند.