
تحلیل عاملی SPSS -آموزش مبتدیان
● بررسی سریع داده ها
● اجرای تحلیل عاملی در spss
● خروجی های تحلیل عاملی در spss
● افزودن امتیازهای عاملی به داده ها
تحلیل عاملی چیست؟
تحلیل عاملی یک تکنیک آماری برای شناسایی عوامل اصلی و اساسی است که توسط تعدادی از متغیرهای مشاهده شده (بسیار زیاد) اندازه گیری شده اند. بسیاری از عوامل اصلی متغیرهایی هستند که اغلب اندازه گیری آنها سخت میباشد مانند IQ , افسردگی و برونگرایی. . برای محاسبه این موارد، سعی میکنیم سوالات چندگانهای بنویسیم که که حداقل بعضی از عوامل را تاحدودی به ما نشان دهد. ایده اصلی در زیر شرح داده شده است.
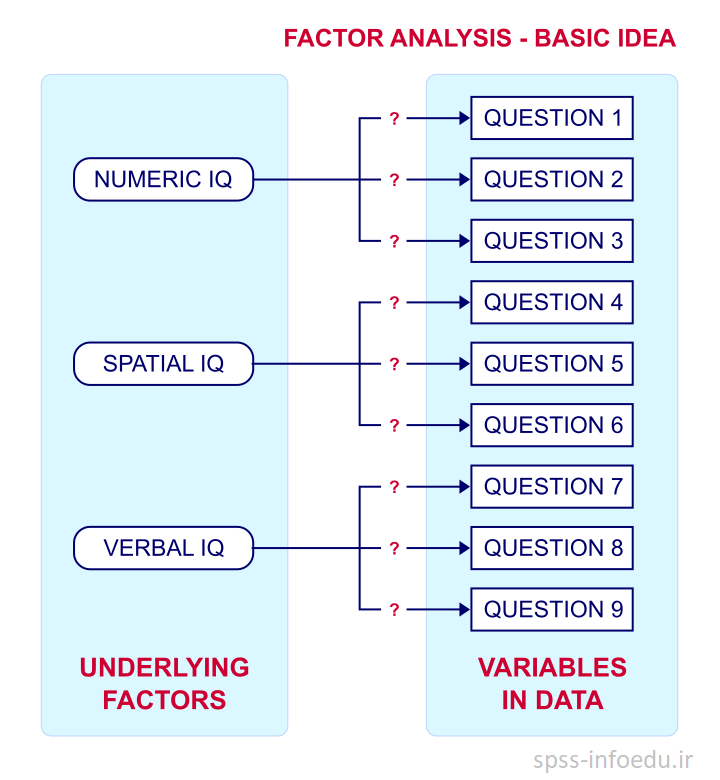
حال اگر سوال ۱، ۲ و ۳ همگی IQ عددی را محاسبه کنند، آنگاه باید همبستگی پیرسون بین این سوالات قابل توجه باشد. پاسخ دهندگان با ضریب هوشی عددی بالا، به طور معمول در هر ۳ سوال نمره بالایی میگیرند و برعکس.
همین استدلال برای سوالات ۴، ۵ و ۶ هم صدق میکند. اگر سوالات دقیقا یک چیز را اندازه گیری کنند، احتمالا همبستگی بالایی دارند. اگر چه سوالات ۱و۴ -که احتمالا ویژگی های نامرتبطی را میسنجند– لزوما ناهمبسته نخواهند بود.
بنابراین اگر مدل عاملی ما درست باشد، انتظار داریم که همبستگی ها از الگوی نمایش داده شده در زیر پیروی کنند.

تحلیل عاملی تاییدی
اکنون پس از سنجش تمام سوالات ۱ تا ۹ در یک نمونه تصادفی ساده از پاسخ دهندگان ، ماتریس همبستگی را محاسبه میکنیم. حال اگر این همبستگی ها نزدیک به هم باشند ، میتوانیم از نرم افزار بخواهیم که مدل عاملی نظری را به ما بدهد. در ای مورد ، ما سعی میکنیم با برازش یک مدل به داده ها و بررسی مناسب بودن آن، از مناسب بودن مدل اطمینان حاصل کنیم . که این کار با عنوان ” تحلیل عاملی تاییدی ” شناخته شده است.
SPSS تحلیل عاملی تاییدی را در برنمیگرد اما علاقه مندان میتوانند از AMOS استفاده کنند.
تحلیل عاملی اکتشافی
حال اگر هیچ اطلاعاتی نداشته باشیم که کدام -یا حتی چه تعداد- عامل توسط داده های ما نشان داده میشوند چکار کنیم؟ در این موارد از نرم افزار میخواهیم که چند مدل را با توجه به ماتریس همبستگی داده شده به ما پیشنهاد دهد. در واقع در این روش ما داده هارا کندوکاو میکنیم . از این جهت به این روش تحلیل عاملی اکتشافی میگویند. ساده ترین توضیح از روش کار در این روش این است که :” نرم افزار تلاش میکند که گروهی از متغیرها را که همبستگی بالایی دارند و بهم پیوسته هستند را پیدا کند. ” . ممکن است هر گروه یک عامل اساسی مشترک را نشان دهد . رویکردهای ریاضی مختلفی برای رسیدن به این هدف وجود دارد اما متداول ترین انها تجزیه و تحلیل مولفه های اصلی یا PCA میباشد. با یک مثال این روش را توضیح خواهیم داد.
سوالات و داده های تحقیق
یک نظرسنجی میان ۳۸۸ نفر متقاضی مزایای بیکاری انجام شده بود. داده های جمع آوری شده در این تحقیق در dole-survey.sav میباشد که بخشی از آن در زیر نشان داده شده است.
این نظرسنجی شامل ۱۶ سوال در مورد رضایت مشتری بود. فرض میکنیم که این سوالات تعداد کمتری از عاملهای اساسی رضایت را بررسی میکنند و ما هیچ اطلاع و سرنخی در مورد چگونگی مدل نداریم . بنابراین سوالات تحقیق برای این تجزیه و تحلیل به این گونه است :
● چه تعدادی از عوامل توسط این ۱۶ سوال اندازه گیری میشوند؟
● کدام سوالها عاملهای مشابهی را اندازه گیری میسنجند ؟
● هر یک از جنبه های رضایت توسط کدام یک از عوامل نشان داده میشود ؟
بررسی سریع داده ها
در ایتدا باید مطمن شویم که یک ایده از اینکه به طور کلی داده هایمان چگونه به نظر میرسند،داشته باشیم. با اجرای دستورات زیر توزیع فراوانی را با استفاده از نمودار های میلهای مربوطه برای ۱۶ متغیر خود بررسی خواهیم کرد.
*Show variable names, values and labels in output tables.
set
tnumbers both /* show values and value labels in output tables */
tvars both /* show variable names but not labels in output tables */
ovars names. /* show variable names but not labels in output outline */
*Basic frequency tables with bar charts.
frequencies v1 to v20
/barchart.
نتیجه
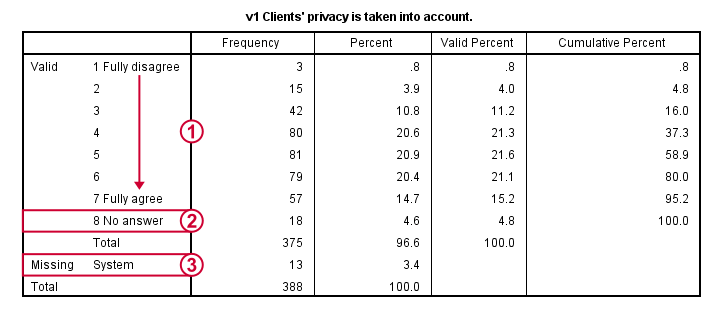
این بررسی بسیار ناچیز داده ها ، اطلاعات کاملا مهمی در مورد داده ها به ما میدهد.
● همهی توزیعات فراوانی قابل قبول به نظر میرسند. ما هیچ چیز عجیبی در داده ها مشاهده نمیکنیم.
● همه ی متغیرها به طور مثبت کدگذاری شده اند : همیشه مقادیر بیشتر بیانگر تمایلات بیشتر به طور مثبت هستند.
● همه ی متغیرها دارای مقدار ۸ (بدون پاسخ) میباشند که ما باید آنها را به عنوان مقدار کاربر از دست رفته در نظر بگیریم .
● همه متغیرها دارای تعدادی مقدار از دست رفته سیستمی هم دارند اما میزان این از دست دادن خیلی بد نیست.
یک نقص تا حدودی ازاردهنده در اینجا این است که ما نمیتوانیم در طرح کلی خروجی، نام متغیر ها را در نمودار میلهای ببینیم.
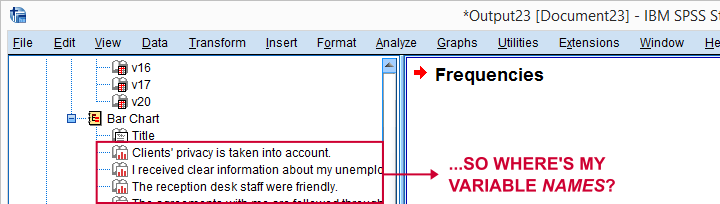
اگر ما یک چیز غیر عادی در نمودار ببینیم ، به راحتی نمیتوانیم به متغیر مربوط به آن مراجعه کنیم. اما در این مثال-خوشبختانه- تمام نمودارها خوب به نظر میرسند.
بنابراین بیایید اکنون مقادیر گم شده خود را تنظیم کرده و چند آمار توصیفی سریع را با کمک دستورات زیر اجرا کنیم :
*Set 8 (‘No answer’) as user missing value for all variables.
missing values v1 to v20 (8).
*Inspect valid N for each variable.
descriptives v1 to v20.
نتیجه

توجه داشته باشید که هیچ یک از متغیرهای ما تعدادی زیادی – بیش از ۱۰ درصد – مقادیر از دست رفته نداشته باشند. با این حال، در کل مجموعه متغیرها فقط ۱۴۸ نفر از ۳۸۸پاسخ دهنده ، هیچ مقدار از دست رفته ای ندارند. این نکته خیلی مهم است که از آنچا که در هر لحظه میبینیم اگاه باشیم.
اجرای تحلیل عاملی در SPSS
حال بیایید همانطور که در زیر نشان داده شده به سمت تجزیه و تحلیل کاهش بعد عاملی برویم.
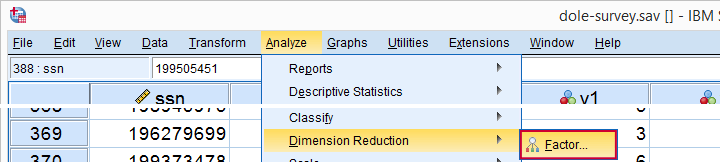
ما تعداد زیادی گزینه در قسمتی که باز میشود داریم ، برای یک تجزیه و تحلیل استاندارد ، گزینه هایی که در زیر نشان داده شده است را انتخاب میکنیم . اگر نمیخواهید تمام گزینه ها را مرور کنید ، میتوانید تجزیه و تحلیل ما را از دستورات زیر تکرار کنید .
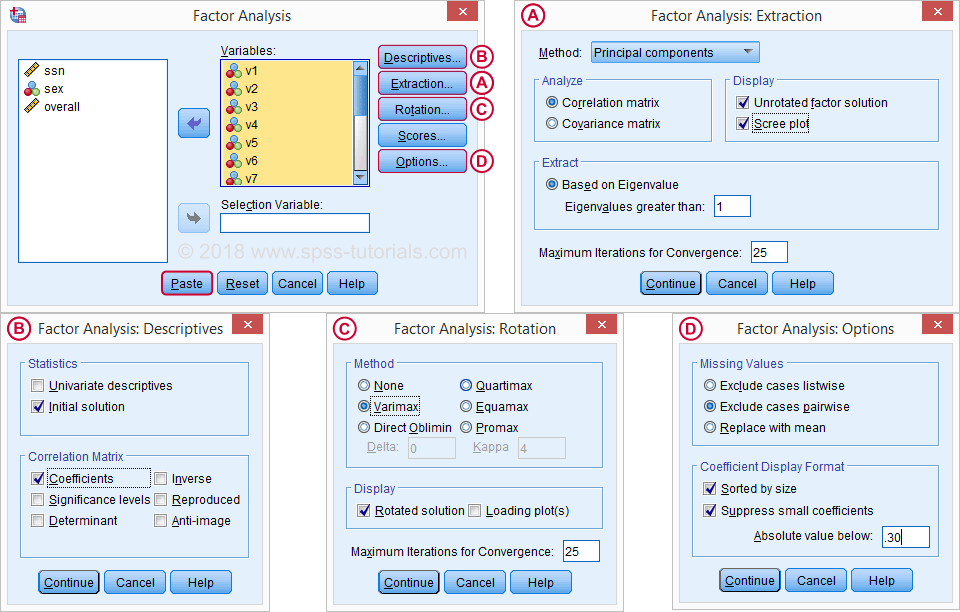
در اینجا از حذف موارد به صورت لیست پرهیز کنید چرا که با این کار ، نرم افزار در تحلیل عاملی فقط ۱۴۸ پاسخ دهندهای که به طور کامل به سوالات پاسخ دادند را در نظر میگرد. کیک کردن گزینه Paste نتایج زیر را به ما میدهد :
دستورات تحلیل عاملی SPSS
*Show both variable names and labels in output.
set
tvars both.
*Initial factor analysis as pasted from menu.
FACTOR
/VARIABLES v1 v2 v3 v4 v5 v6 v7 v8 v9 v11 v12 v13 v14 v16 v17 v20
/MISSING PAIRWISE /*IMPORTANT!*/
/PRINT INITIAL CORRELATION EXTRACTION ROTATION
/FORMAT SORT BLANK(.30)
/PLOT EIGEN
/CRITERIA MINEIGEN(1) ITERATE(25)
/EXTRACTION PC
/CRITERIA ITERATE(25)
/ROTATION VARIMAX
/METHOD=CORRELATION.
اولین خروجی تحلیل عاملی – واریانس کلی
اکنون با ۱۶ متغیر ورودی ، PCA در ابتدا ۱۶ عامل(یا مولفه) را استخراج میکند. هر مولفه یک درجه کیفیتی دارد که آن را مقدار ویژه مینامند. احتمالا فقط مولفههای دارای مقادیر ویژه بالا عامل های اساسی واقعی را نشان میدهند .
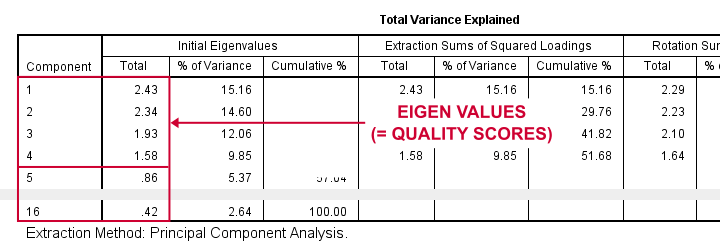
پس مقدار ویژه بالا چیست؟ یک قاعده کلی رایج ،انتخاب مولفه های اصلی که حداقل مقدار ویژه آنها ۱ است میباشد. استفاده از این قانون ساده در جدول قبلی به اولین سوال تحقیق ما پاسخ میدهد. به نظر میرسد ۱۶ متغیر ما ۴ عامل اصلی را اندازه گیری میکنند. چرا که فقط ۴ مولفه اول دارای مقدار ویژهای با مقدار حداقل ۱ میباشند.فرض میکنیم مولفه های دیگر -دارای مقادیر ویژه کم- ویژگی های واقعی و اساسی ۱۶ سوال مارا نشان نمیدهند . این مولفه ها همانطور که در نمودار خطی زیر نشان داده شده است، scree در نظر گرفته میشوند .
دومین خروجی تحلیل عاملی – نمودار scree
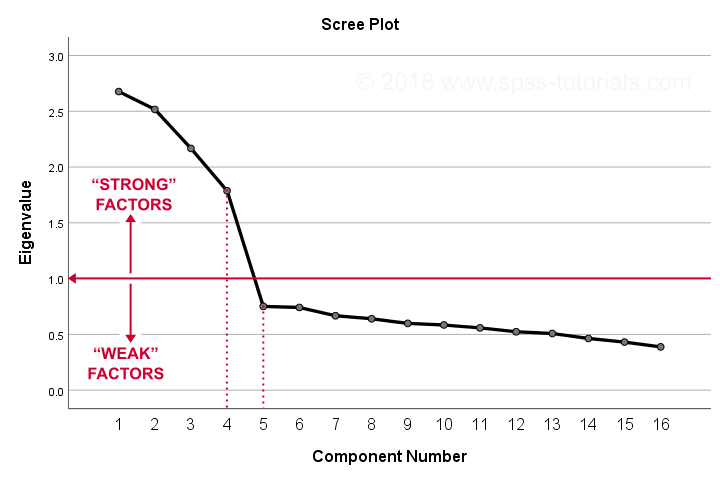
نمودار scree مقادیر ویژهای که میبینیم را به تصویر میکشد. مجددا مشاهده میکنیم که ۴ مولفه اول دارای مقادیر ویژهای بیشتر از یک میباشند. ما این مولفه هارا به عنوان مولفههای قوی در نظر میگیریم. بعد از آن -مولفههای ۵ به بعد- مقادیر ویژه به طور چشمگیری کاهش می یابد. این افت شدید بین مولفه های ۱تا۴ و ۵تا۱۶ به طور قوی نشاندهندهی این است که ۴ عامل پایه و اساس سوالات ما است .
سومین خروجی تحلیل عاملی – مشترکات
پس ۴عامل اساسی ما واریانس ۱۶ متغیر ورودی را تا چه اندازه محاسبه میکنند؟ جواب این سوال مقادیر مربع r (r2)میباشد ،چیزی که -به دلایلی نامعلوم- در تحلیل عاملی مشترکات نامیده میشود .
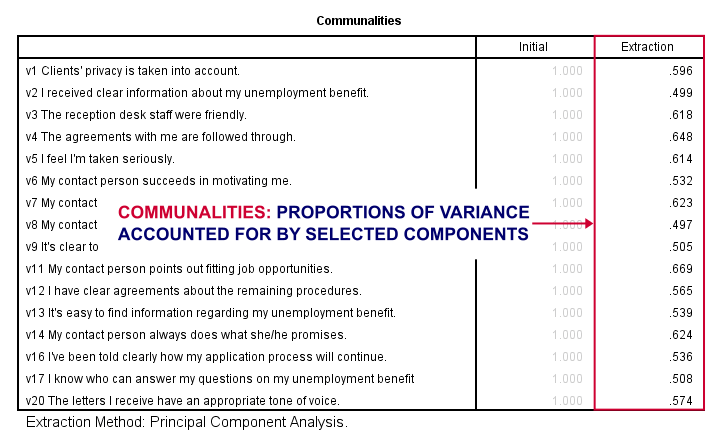
حال اگر ما از ۴ مولفه و به روش رگرسیون چندگانه v1 را پیش بینی کنیم ، r2 برابر با ۰.۵۹۶ -مشترکات v1 – خواهد شد. متغیرهایی که مشترکات کمی دارند (گفته شده کمتر از ۰.۴۰) خیلی برای محاسبهی عوامل اساسی کمک کننده نیستند.
شما میتوانید چنین متغیرهارا از تجزیه و تحلیل حذف کنید. اما در نظر داشته باشید که این کار موجب تغییر همه نتایج میشود. بنابراین شما باید کل تجزیه و تحلیل را مجددا با یک متغیر حذف شده اجرا کنید. و شاید مجددا این کار را با یک متغیر کنار گذاشته شده دیگر تکرار کنید .
اگر نمودار scree این مسئله را توجیه کند ،میتوانید یک مولفه اضافی را نیز انتخاب کنید . اما اگر این عمل موجب شد که ماتریس بارعاملی سختتر تفسیر شود، از انجام این کار پرهیز کنید.
چهارمین خروجی تحلیل عاملی – ماتریس مولفه ها
تا به اینجا نتیجه گرفتیم که ۱۶ متغیر ۴ عامل اصلی را اندازه گیری میکنند. اما کدام یک از آنها کدام عامل را اندازه گیری میکند؟ ماتریس مولفه ها همبستگی پیرسون بین بخشهای مختلف و مولفه ها را نشان میدهد . به دلایلی نامعلوم این همبستگی بار عاملی نامیده میشود.

به طور ایده آل ، ما میخواهیم که هر متغیر ورودی دقیقا یک عامل را اندازه گیری کند. متاسفانه در اینجا اینطور نیست. برای مثثال متغیر v9 مولفه های ۱و ۳ را اندازه گیری میکند (با انها همبستگی دارد). حتی بدتر ، v3 و v11 مولفه های ۱،۲و ۳ را به طور همزمان اندازه گیری میکنند. اگر هر متغیربیشتر از یک بارعاملی و مهم و تاثیر گذار داشته باشد، آنها را بار عاملی متقاطع مینامیم . این متغیرها مورد پسند ما نیستند و تفسیر عاملهای مارا پیچیده تر میکنند .
راه حل این مشکل دوران میباشد: ما بارهای عاملی را بر اساس برخی از قوانین ریاضی بر روی عاملها توزیع میکنیم که این کار به SPSS واگذار خواهیم کرد. با این کار آنچه که مولفه های ما نشان میدادند دوباره تعریف میشوند . اما مشکلی نیست. به هر حال ما هنوز این مسئله را بررسی نکرده بودیم.
روشهای دوران متفاوتی وجود دارد اما رایج ترین آنها روش واریماکس (varimax)میباشد. که این کلمه کوتاه شدهی “ماکسیمم سازی و بیشینه سازی متغیر” میباشید . در این روش تلاش بر این است که بارهای عاملی را مجدا توزیع کنیم به گونه ای که هر متغیر دقیقا یا عامل را اندازه گیری کند- چیزی که وضعیت بسیار خوب و ایده آلی برای فهمیدن و شناخت عاملها میباشد . و همانطور که میبینیم ، دوران واریماکس کاملا برای داده های ما خوب عمل میکند.
پنجمین خروجی تحلیل عاملی – ماتریس مولفه های دوران یافته
ماتریس مولفه های دوران یافته ی ما (در زیر آمده) به دومین سوال تحقیق ما ” کدام متغیر کدام عامل را اندازه گیری میکند؟ ” پاسخ میدهد.

آخرین سوال تحقیق ما این است که :” عاملهای ما دقیقا چه چیزی را نشان میدهند؟” به طور فنی یک عامل(یا مولفه) هر چیزی را که با متغیرهای خود در اشتراک دارد نشان میدهد. ماتریس مولفه های دوران یافته ما(بالا) نشان دهندهی این است که مولفه اول اندازه گیری شده توسط :
● V17 : من میدانم چه کسانی میتوانند به سوالات من در مورد مزایای بیکاری پاسخ دهند.
● V16 : به من به طور واضح گفته شده است که روند درخواستهای من چگونه ادامه می یابد.
● V13 : یافتن اطلاعاتی مربوط به مزایای بیکاری کاری آسان است.
● V2 : من اطلاعات واضحی در رابطه با مزایای بیکاری دریافتهام.
● V9 : برای من روشن است که حقوق من چیست .
توجه داشته باشید که همه این متغیرها به دریافت پاسخ واضح از پاسخ دهنده بستگی دارد. بنابراین، ما مولفه اول را با عنوان “وضوح اطلاعات” تفسیر میکنیم. این یک ویژگی اساسی است که توسط v17,v16,v13 و v9 اندازه گیری میشود.
پس از تفسیر تمام مولفه ها با روشی مشابه ، به سوالات زیر میرسیم :
● مولفه اول :ِ وضوح اطلاعات
● مولفه دوم : انطباق داشتن و مناسب بودن
● مولفه سوم : ارتباطات مردمی مفید
● مولفه چهارم : قابل اطمینان بودن توافقات
ما بعد از افزودن نمرات عاملی به داده هایمان ، اینهارا به عنوان برچسبهای متغیر یا نام متغیر در نظر میگیریم.
افزودن نمرات عاملی به داده هایمان
افزودن نمرات واقعی مولفه با داده ها کاری معمول است. آنها اغلب به عنوان پیش بینی کننده در تحلیل رگرسیون و یا محرک در نمونه گیری خوشهای استفاده میشوند. SPSS FACTOR میتواند نمرات مولفه ها را به داده های شما اضافه کند اما این عمل به دو دلیل ایده بدی است :
● نمرات عاملی فقط به مواردی که در هیچ یک از متغیرهای ورودی مقدار از دست رفته نداشته باشد افزوده میشود . دیدیم که این مطلب فقط برای ۱۴۹ مورد از ۳۹۹ مورد ما صدق میکند.
● نمرات عاملی ، نمرات استاندار (z-factor ) میباشند : میانگین آنها صفر و انحراف معیار آنها ۱ میباشد. که این مورد موجب پیچیدگی تفسیر میشود.
در بسیاری از موارد، ایده بهتر محاسبه نمرات عاملی به عنوان میانگین بیشی از متغیرهای اندازه گیری عوامل مشابه میباشد. این میانگین ها تقریبا-کاملا با نمرات عاملی واقعی ارتباط دارند اما مشکلات ذکر شده تاثیر منفی روی آنها ندارد و موجب ایجاد خلل در آنها نمیشود. نکته مهم ، فقط در صورتی این کار را انجام میدهیم که تمام متغیرهای ورودی مقیاس اندازه گیری یکسانی داشته باشند. از آنجایی که این نکته برای مثال ما صدق میکند ، با دستورات زیر نمرات عاملی را اضافه خواهیم کرد.
محاسبه و نامگذاری دستورات نمرات عاملی
*Create factors as means over variables per factor.
compute fac_1 = mean(v16,v13,v17,v2,v9).
compute fac_2 = mean(v3,v1,v5,v20).
compute fac_3 = mean(v11,v7,v6,v8).
compute fac_4 = mean(v4,v14,v12).
*Label factors.
variable labels
fac_1 ‘Clarity of information’
fac_2 ‘Decency and appropriateness’
fac_3 ‘Helpfulness contact person’
fac_4 ‘Reliability of agreements’.
*Quick check.
descriptives fac_1 to fac_4.
نتیجه
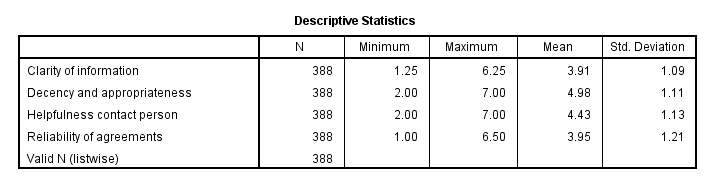
این جدول توصیفی ، نحوه تفسیر عاملهای خود را نشان میدهد. از آنجایی که ما آنها را به عنوان میانگین محاسبه کردیم، مقیاسهای متغیرهای ورودی ما از ۱تا۷ یکسان است . این نکته به ما اجازه میدهد که نتیجه گیری کنیم.
● منطبق بودن و مناسبت داشتن مدل به بهترین صورت رتبه بندی شده است (تقریبا نمره ۵ از ۷ ) و
● وضوح اطلاعات بدترین رتبه را دریافت کرده است (تقریبا ۳.۹ از ۷نمره).