مقادیرگمشده سیستمی فقط در متغیرهای عددی یافت می شود. در مقادیر گمشده سیستمی ،متغیرهای متنی،وجود ندارد. داده ها به چندین دلیل ممکن است در سیستم به صورت مقادیر گمشده باشند:
● برخی از پاسخ دهندگان به دلیل روند پرسشنامه به بعضی سوالات پاسخ نمی دهند.
• پاسخ دهنده از برخی سوالات گذر کرده است.
• گاهی در حین وارد کردن یا ویرایش داده ها مشکلی به وجود می آید.
• برخی از مقادیر به دلیل خرابی تجهیزات ثبت نشده اند.
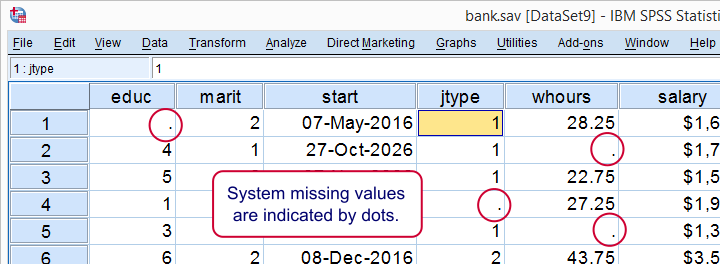
در بعضی موارد مقادیر گمشده سیستمی کاملاً منطقی است.مثلا بپرسیم که “آیاماشین دارید؟” و پاسخ دهنده “خیر” جواب دهد. پس نرم افزاردراین نظرسنجی باید ازپرسیدن سوال بعدی امتنا کند: “ماشین شما چه رنگیست؟” احتمالا در داده های سیستم ، برای افرادی که ماشین ندارند،مقادیر گمشده ای مشاهده کنیم.این نوع از مقادیر گمشده، کاملا منطقیست.
با این حال ، دربرخی ازموارد هم ، ممکن است مشخص نباشد که چرا مقادیر در سیستم از دست رفته است. ممکن است مشکلی پیش آمده باشد یاخیر . بنابراین ، باید سعی کنید دلیل وجود مقادیر گمشده سیستمی را متوجه شوید به خصوص اگر تعدادشان زیاد باشد.
حال،چگونه می توان مقادیرگمشده از داده هایمان را شناسایی و کنترل کنیم؟
پس از نگاهی به نوع دوم مقادیر از دست رفته به آن خواهیم رسید.
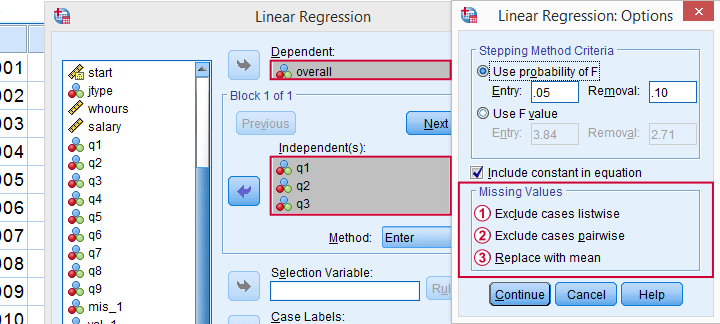
مقادیر گمشده کاربردر SPSS
به مقادیری که هنگام تجزیه و تحلیل یا ویرایش داده ها،قابل بررسی نیستند،مقادیر گمشده کاربرمی گویند. “کاربر” در اینجا به کاربرspss اشاره دارد.که شمایید!!
درنتیجه،این شماهستید که گاهی ممکن است لازم باشد،برخی ازمقادیر را به عنوان مقادیر گمشده کابر درنظر بگیرید. . بنابراین کدام داده ها – در صورت وجود – باید کنارگذاشته شوند؟ به طور خلاصه،
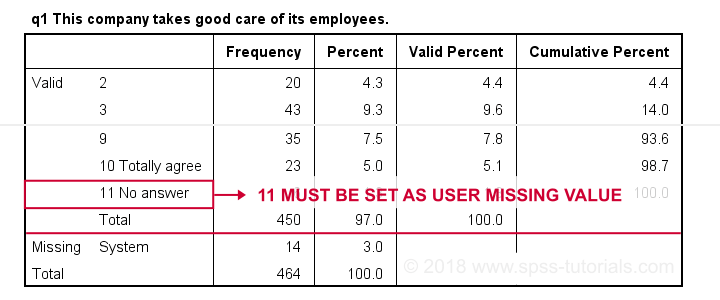
• برای متغیرهای رسته ای ، به طور معمول پاسخ هایی مانند “نمی دانم” یا “بدون پاسخ” از تجزیه و تحلیل حذف می شوند.
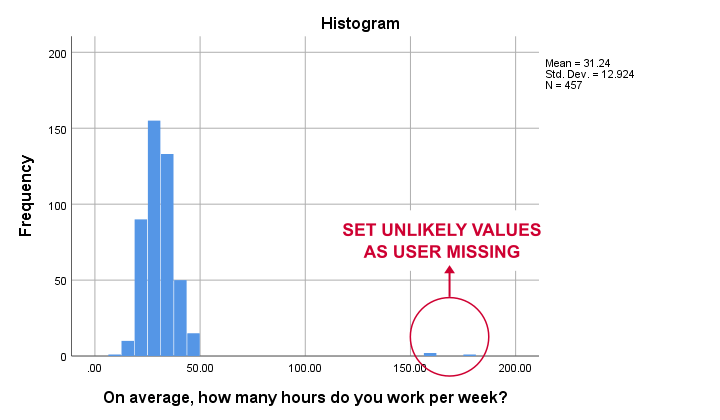
• برای متغیرهای متریک، مقادیرغیرمحتمل – زمان واکنش 50 میلی ثانیه یا حقوق ماهیانه 9999999 یورو – معمولاً به عنوان مقدارگمشده کاربر درنظر گرفته می شوند.
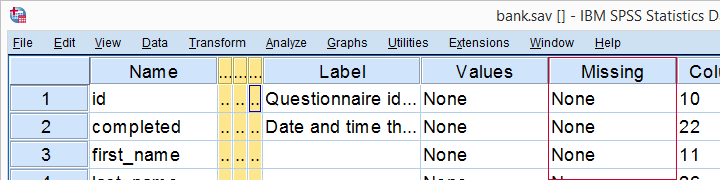
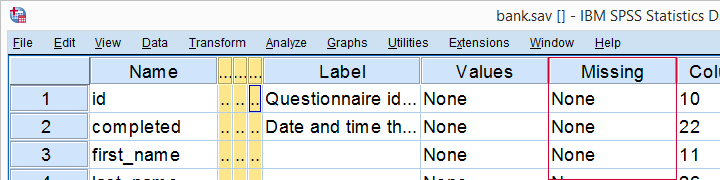
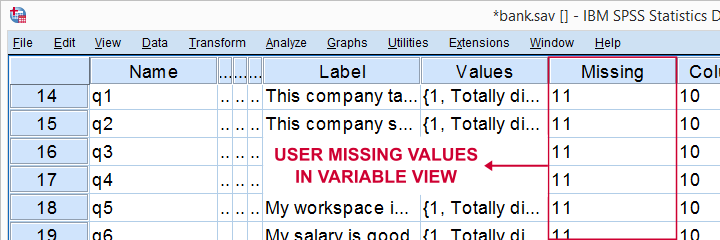
رای bank.sav، هنوز هیچ مقدار گمشده کاربر تنظیم نشده است، همانطور که در variable view مشاهده می شود.