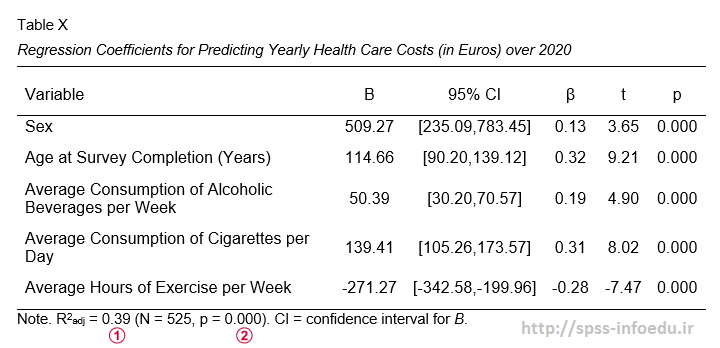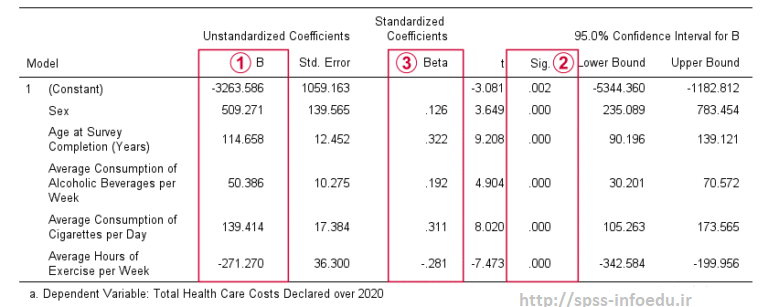
ضرایبb مدل رگرسیون ما را مشخص می کنند:
$Costs’ = -3263.6 + 509.3 \cdot Sex + 114.7 \cdot Age + 50.4 \cdot Alcohol\\ + 139.4 \cdot Cigarettes – 271.3 \cdot Exericse$
(\cdot) هزینه های بهداشتی سالیانه پیش بینی شده را به دلار نشان می دهد.
![]()
هر ضریب b میانگین افزایش هزینه های مرتبط با افزایش 1 واحد در یک پیش بینی را نشان می دهد. به عنوان مثال ، افزایش 1 ساله در سن به طور متوسط 114.7 دلار در هزینه ها افزایش می یابد. یا افزایش 1 ساعته ورزش در هفته با افزایش – 271.3 دلار (یعنی 271.3 دلار کاهش) هزینه های سالانه سلامتی همراه است.
حال بیایید، در مورد جنسیت صحبت کنیم: افزایش 1 واحدی جنسیت ، به طور متوسط 509.3 دلار هزینه هارا افزایش می یابد. برای درک معنای این مورد ، لطفا توجه داشته باشید که جنسیت در داده های مثال ما 0 (زن) و 1 (مرد) رمزگذاری شده است. بنابراین برای این متغیر ، تنها افزایش 1 واحدی ممکن است از زن (0) به مرد (1) باشد. بنابراین ، 509.3B =$ به این معناست که بطور متوسط سالانه هزینه ها بر ای مردان 509.3 دلار بالاتر از زنان است (هر چیز دیگری برابر است ، یعنی). این چگونگی استفاده از متغیرهای دوحالته در رگرسیون چندگانه را روشن می کند. وقتی متغیر های تصنعی را آموزش دهیم این ایده را توضیح خواهیم داد.
ستون “Sig” در جدول ضرایب ما شامل (2مقدار) p-valueبرای هر ضریب b است. به عنوان یک دستورالعمل کلی ، ضریب b از نظر آماری معنی دار است اگر “Sig” یا p < 0.05باشد. بنابراین ، تمام ضرایب b در جدول ما از نظر آماری معنی دار هستند. دقیقاً ، مقدار p-value= 000 به این معنی است که اگر برخی از ضرایب b در جامعه صفر باشد (فرضیه صفر) ، در این صورت احتمال یافتن مشاهده ای از نمونه با ضریب b یا شدیدتر 0.000 است. سپس نتیجه می گیریم که احتمالاً ضریب b جامعه صفر نبوده است.
ضرایب b ، قدرت نسبی پیش بینی کننده های ما را به ما نمی گویند. دلیل این امر این است که مقیاس های مختلفی دارند: آیا یک سیگار در روز بیشتر از یک نوشیدنی الکلی در هفته است یا کمتر؟ یک راه برای مقابله با این ، مقایسه ضرایب رگرسیون استاندارد یا ضرایب بتا است که اغلب به صورت β (حرف یونانی “بتا”) نشان داده می شود. *
ضرایب بتا (ضرایب رگرسیون استاندارد) برای مقایسه نقاط قوت نسبی پیش بینی کننده های ما مفید است. 3 پیش بینی کننده قوی در جدول ضرایب ما عبارتند از:
- سن (β = 0.322) )؛
- مصرف سیگار (β = 0.311);
- ورزش (β = -0.281).
ضرایب بتا با استاندارد سازی همه متغیرهای رگرسیون (عدد z استاندارد) قبل از محاسبه ضرایب b بدست می آیند. استاندارد سازی متغیرها یک معیار(یا مقیاس) مشابه را برای آنها اعمال می کنند: نتایج عدد z همیشه میانگین 0 و انحراف استاندارد 1 به دنبال دارد.
این مطلب بدون توجه به اینکه آیا سیگار یا نوشیدنی های الکلی در طول سال به چه میزان محاسبه می شوند، درنظر گرفته می شود. به همین دلیل است که ضرایب B بیش از متغیرهای استاندارد استفاده می شوند در حالی که ضرایب بتا در مدلهای رگرسیونی درونی وبیرونی قابل مقایسه هستند.
بنابراین ضرایب b مدل رگرسیون چندگانه ما را تشکیل می دهند. این به ما می گوید که چگونه می توان هزینه های سالانه مراقبت های بهداشتی را پیش بینی کرد. آنچه که ما نمی دانیم ، این است که چقدر مدل ما این هزینه ها را پیش بینی می کند؟ پاسخ را در جدول خلاصه مدل در زیر می یابیم.